Cette page a été rédigé en 1993, elle n'est plus vraiment à jour, même si il n'y a aucune erreur factuelle
Les réseaux de neurones
1.1 L’argument physiologique
L’idée du réseau de neurones formels vient de l’étude du cerveau
humain. Ce qui suit n’est qu’une vision très
schématique du fonctionnement du dit cerveau1.
Le cerveau humain est composé d’un
ensemble de cellules appelées neurones. Un neurone est composé
d’un noyau, de connexions entrantes (les dendrites)
et d’une connexion sortante, l’axone. L’influx nerveux se
déplace toujours des
dendrites vers le noyau, et du noyau vers l’axone. L’influx transmis
dans l’axone
est fonction de la valeur de l’influx dans chacune des dendrites. Certaines
dendrites peuvent avoir un effet moteur favorisant la transmission d’une
information dans l’axone, d’autres au contraire ont un effet
inhibiteur qui bloque la transmission de l’influx dans l’axone.
Il semble que le
noyau agisse comme un
sommateur des influx venant des dendrites, en affectant un
poids (qui peut être négatif) à chacune d’entre elles. Si la somme des
influx est supérieure à un seuil, un influx est transmis dans l’axone.
Si la somme est inférieure à ce seuil, aucun signal n’est transmis.
Un axone peut, par la suite, soit se subdiviser
en plusieurs filaments qui serviront
chacun d’entrée à d’autres neurones en se connectant aux dendrites de ces
neurones via des synapses, soit attaquer directement un
élément moteur (muscle par exemple).
McCulloch et Pitts sont les << pères >> du modèle mathématique du
neurone [MP43]. On peut le résumer de la façon suivante ; on pose pour
un neurone :
| Ii∈ ℝ | : entrées du neurone |
| Wi∈ ℝ | : poids correspondant à chacune des entrées |
| θ | : seuil |
| O∈ ℝ | : sortie du neurone |
| f(x) | : fonction de seuil vérifiant ∀ x, x>θ, f(x)=1
et f(x)=0 sinon. |
Alors
Nous allons dans ce chapitre nous intéresser à différentes
techniques mettant en œuvre des réseaux de neurones dans le sens
large du terme. Nous allons nous apercevoir qu’il existe de nombreuses
approches différentes, ayant des buts différents. Les
gens intéressés par le domaine peuvent se reporter, par exemple, à
[HKP91] (remarquable) ou
[HN90] pour une vision d’ensemble des techniques basées sur
les réseaux de neurones, ou en français [DN86] qui est
un peu plus ancien, ou l’excellent [BRS91].
1.2 Les mémoires associatives et le modèle de Hopfield
Dans une mémoire associative, nous stockons dans un réseau de
neurones un certain nombre de formes et, en fournissant au
réseau une partie d’une des formes stockées, nous souhaitons que
le réseau reconstitue l’intégralité de la forme stockée.
Un exemple typique d’utilisation d’une mémoire associative est la
reconnaissance et la reconstruction d’images. On stocke dans le réseau
un certain nombre d’images. Le réseau doit par la suite reconstruire
à partir d’un détail qu’on lui fournit l’ensemble de l’image la plus proche
de ce détail.
Nous allons détailler dans cette section la façon dont
fonctionne une mémoire associative.
1.2.1 Modèle mathématique
Nous allons considérer un réseau comportant N neurones. Tous les neurones
sont connectés les uns aux autres2. Chacun des neurones pourra fournir une valeur d’activation +1 ou
−1. La valeur d’activation de l’unité i sera donnée par la formule :
où les Wji sont les poids du réseau et où S est la fonction
<< Signe >> définie par :
| S(x)=1 si x≥ 0, et S(x)=−1 si x<0 |
Supposons maintenant que nous souhaitions faire évoluer notre réseau. Il
est possible de le faire de façon synchrone ou de facon asynchrone. Dans le mode synchrone, tous les éléments du réseau
évoluent en même temps en appliquant simultanément
l’équation 1.1. Dans le mode asynchrone, les unités évoluent
les unes après les autres, de façon aléatoire par exemple. Dans le
cas des mémoires associatives, il est de coutume d’utiliser le
mode asynchrone de préférence au mode synchrone.
1.2.2 Mémorisation d’un vecteur binaire
Supposons que nous voulons que notre réseau mémorise
le vecteur binaire O→1=(O11,O21,…,On1). Ceci
signifie que toutes les valeurs Oi1 doivent être stables par
application de la transformation 1.1 ; donc, il faut :
Ceci est clairement le cas si nous prenons :
Par mesure de simplicité, on pose généralement :
On constate que tout vecteur O→k=(Oik) sera, s’il est proche
de O→1 dans l’espace de Hamming3, << attiré >> vers O1. En effet,
soit le terme :
Ce terme sera égal à Oj1 si la somme ∑i Oi1
Oik est positive, c’est-à-dire si le nombre de Oik égaux à
Oi1 est supérieure à N/2. Donc, pour tout vecteur initial
situé à une distance de Hamming4 inférieure à N/2 de Oi1,
le réseau évoluera vers O→1. O→1 est un attracteur. On voit réciproquement que, pour tout vecteur situé à une
distance de Hamming supérieure à N/2, le réseau évoluera vers
l’attracteur inverse, qui est −O→1.
1.2.3 Mémorisation de plusieurs vecteurs binaires
Comment faire pour mémoriser simultanément P vecteurs binaires dans un
même réseau ? Il suffit de superposer plusieurs termes de la
forme 1.2, ce qui donne pour les poids :
Cette règle est appelée règle de Hebb, ou règle de Hebb
généralisée. Un réseau qui utilise la règle de Hebb pour le
calcul des poids des connexions et qui effectue la mise à jour des valeurs
des unités de façon asynchrone est un modèle de Hopfield.
Il nous reste à montrer que la règle choisie pour calculer les poids
vérifie bien les conditions de stabilité pour l’ensemble des vecteurs
O→k. Nous voulons donc :
| ∀ k, ∀ j, S( | | Wji Oik) = Ojk |
Développons rapidement :
| = | |
| | = | | S( | | | | Ojk Oik Oik
+ | | | | | | Ojl Oil Oik) |
|
| | = | |
|
Nous voyons qu’une condition suffisante pour que ce terme soit égal à
Ojk est :
Ceci est en général le cas si le nombre de vecteurs stockés P est
petit devant le nombre total de neurones N. Nous allons étudier le
problème de la capacité de stockage dans la section suivante.
Remarquons cependant que si la condition 1.3 est vérifiée,
chacun des vecteurs stockés agira comme un attracteur par rapport aux
vecteurs proches de lui dans l’espace de Hamming, pour des raisons
absolument similaires à celles développées dans la section
précédente.
1.2.4 Capacité de stockage
Nous allons dans cette section nous intéresser à la capacité de
stockage d’un réseau de Hopfield, c’est à dire au nombre de vecteurs binaires
différents qu’il est capable de stocker simultanément en fonction du nombre de
neurones5.
Posons :
D’après les résultats de la partie précédente, nous savons que les
vecteurs binaires sont stables si la condition suivante est vérifiée
pour tout j et tout k :
Nous allons nous intéresser au cas où tous les vecteurs O→k sont
composés de bits aléatoires. Nous allons également considérer que le
nombre de neurones N et le nombre de vecteurs stockés P sont grands
devant 1. Nous allons tout d’abord calculer la probabilité pe pour
qu’un bit j d’un vecteur k ait une valeur incorrecte :
N et P étant grands devant 1, on peut approximer Tjk à
1/N fois la somme de N × P nombres valant aléatoirement 1 ou
−1. Il s’agit donc d’une distribution binomiale de moyenne 0 et de
variance σ2=P/N. N × P étant grand devant 1, on peut
approcher cette loi binomiale par une gaussienne. Dans ce cas, pe se
calcule facilement et vaut :
On peut calculer des valeurs numériques de pe pour tout σ.
Réciproquement, si nous fixons pe, il est possible de calculer la
valeur de σ. Ainsi, par exemple, si l’on souhaite que la probabilité
d’erreur pour un bit6 soit inférieure à 1%,
il faut prendre σ=0.185, soit P<0.185N.
Calculons maintenant la condition pour que 99% des bits soient
correctement mémorisés, soit (1−pe)N>0.99 puisque chaque vecteur
contient N bits. Comme pe sera certainement petit devant 1, on peut
faire un développement limité à l’ordre 1 et ramener cette condition
à pe<0.01/N. Ceci impose que σ=P/N tend vers 0 quand N tend
vers l’infini. On peut donc faire un développement asymptotique de
log(pe) et on obtient :
| log(pe) ≈ −log2 − | | − | | logπ − | | log(N/2P) |
La condition pe<0.01N devient, en passant au log :
| log(pe)<log(0.01) − log(N) |
Ce qui nous donne donc, en ne gardant que les termes principaux en N :
Si l’on souhaite que tous les vecteurs binaires appris soient
parfaitement restitués, il faut alors exiger que les NP bits soient
restitués avec une probabilité de 99%, soit
En approximant NP par N2 pour N grand, on obtient :
Si nous nous résumons, on peut donc dire que le nombre de vecteurs
binaires que peut retenir un réseau dépend linéairement du nombre N
de neurones (de l’ordre de 0.10× N), à condition que l’on accepte
un certain nombre d’erreurs dans la restitution. Si l’on souhaite une
restitution proche de la perfection, alors la capacité de mémorisation
est de l’ordre de N/log(N).
1.3 Les réseaux à sens unique
Nous allons, dans cette section, nous intéresser à des réseaux
constitués de couches de neurones dans lesquels la sortie d’un neurone ne
peut alimenter que l’entrée d’un neurone situé dans une couche
postérieure
et nous allons étudier dans ces réseaux les mécanismes
d’auto-apprentissage, ainsi que leurs justifications théoriques. On parle
ici d’apprentissage supervisé.
Ces réseaux ne fonctionnent pas sur le principe de
mémoire associative. Les poids des connexions sont au départ
aléatoires et c’est par un mécanisme
essai-erreur-correction que ce type de réseau évolue vers un état
stable. Historiquement, les premiers réseaux ayant fonctionné
sur ce mécanisme furent les perceptrons, développés par
Rosenblatt dès 1958 [Ros58, Ros62]. Mais
en 1969, Minsky et Papert [MP69]
montreront que les perceptrons ne peuvent s’appliquer que pour des
classes d’exemples linéairement séparables. Ainsi, un perceptron
ne peut apprendre une fonction de type OU-exclusif.
L’intérêt pour les réseaux de neurones disparut un peu,
malgré les améliorations apportées au système par la règle
de Widrow-Hoff. En effet, on ne savait pas réaliser l’apprentissage
pour des réseaux
à plus de deux couches. Cette limite disparut dans les années 80
avec la découverte d’une méthode permettant d’étendre la
règle de Widrow-Hoff aux réseaux multi-couches.
Pour plus de précision, on peut se reporter à [Sou86] ou
[Rum86]. Nous allons, dans la suite de cette section, examiner le
cas des réseaux à deux couches et à couches multiples. Nous
n’étudierons pas les perceptrons.
1.3.1 Les réseaux à deux couches
Nous allons examiner, comme premier exemple, les réseaux à deux couches.
Dans ces réseaux, la première couche est appelée couche d’entrée
et la seconde couche, couche de sortie. Chaque neurone de la couche d’entrée
est raccordé à chaque neurone de la couche de sortie au moyen d’une
synapse. Les neurones de sortie additionnent la somme des valeurs que leur
envoient les neurones d’entrée en leur affectant un poids.
Mathématiquement, on peut noter7 :
Au départ, les poids Wji sont quelconques. Le but de la
méthode
d’apprentissage est de les faire évoluer de
façon à ce que le réseau soit capable, étant donné un vecteur d’entrée, de
calculer le bon vecteur en sortie.
Le mécanisme utilisé est le suivant : on fournit au réseau un
ensemble d’exemples. Chaque exemple est constitué d’un vecteur d’entrée et
du vecteur de sortie correct associé. On demande alors au réseau de
calculer, pour chaque vecteur d’entrée,
son propre vecteur de sortie et on le
compare au vecteur correct. En fonction de l’erreur, on modifie les
Wji jusqu’à ce que le réseau donne une réponse que l’on estime
correcte (c’est-à-dire jusqu’à ce que l’erreur entre le vecteur
théorique et le vecteur calculé soit inférieure à une valeur
considérée comme raisonnable). Ce type de mécanisme est
également appelé apprentissage
supervisé,
car on << supervise >> l’apprentissage en fournissant des exemples au
réseau.
Comment est calculée la modification des poids ? La formule utilisée est
la suivante :
| Δ Wji = η (Tj − O j) Ii = η δj Ii
|
η représente le coefficient d’apprentissage, T le
vecteur théorique en sortie, O le vecteur calculé par le réseau en sortie
et I le vecteur en entrée et δj = Tj−Oj.
Cette règle est appelée règle du delta (delta-rule par les
anglo-saxons).
Nous allons maintenant montrer que cette règle est valable8 et minimise bien
l’erreur sur un exemple (I,T).
Pour cela, nous allons prouver que la dérivée de la fonction d’erreur du
réseau par rapport à chacun des poids est proportionnelle au changement
dans les poids préconisés par la règle du delta, affectée du
signe moins. Cela prouvera que la règle delta modifie les poids suivant la
courbe de plus grande pente sur la surface définie par la fonction d’erreur.
Nous allons tout d’abord poser :
E représente l’erreur entre la sortie désirée T et la
sortie
calculée O. Nous allons maintenant prouver que :
Nous allons décomposer ∂ E/∂ Wji
en deux termes :
La première partie indique comment l’erreur change quand
la sortie change, et la seconde comment la sortie varie en fonction des
poids. Il est maintenant facile de calculer les deux membres. Tout
d’abord de l’équation 1.5 nous tirons :
Comme on pouvait s’y attendre, la contribution d’une unité à
l’erreur est proportionnelle à δj. De plus de
l’équation 1.4, nous tirons :
En substituant dans l’équation 1.6,
QED.
Il nous reste à montrer que cette règle minimise aussi l’erreur totale
pour un ensemble (Ip,Tp) d’exemples. L’erreur totale E
vaut :
avec , comme nous venons de le voir :
On a alors, à partir de 1.8 et de 1.7 :
On voit donc que l’erreur est minimisée à condition que les poids Wji
ne soient pas modifiés entre chaque exemple. Or, c’est
précisément ce que fait la règle du delta. C’est là qu’intervient
la constante η. En effet, pour η petit, la variation des Wji
est négligeable par rapport à la variation de l’erreur et la méthode
reste valable.
1.3.2 Les réseaux multi-couches
Un réseau multi-couches est constitué d’une couche d’entrée,
d’une couche de sortie et de couches intermédiaires. Un neurone ne peut
envoyer son résultat qu’à un neurone situé dans une couche
postérieure à la sienne. Un vecteur d’entrée étant donné, on
calcule le vecteur de sortie par passes successives à travers les couches.
Enfin, des résultats théoriques montrent que pour tirer parti de
ce type de réseau, il faut utiliser des fonctions d’activation
non-linéaires. Jusqu’à présent nous avions utilisé comme
fonction d’activation l’identité, puisque nous
écrivions9 :
Oj = ∑i (Wji Oi).
Désormais nous poserons :
et
où f est une fonction non-décroissante et différentiable.
Pour prouver que nous pouvons toujours appliquer une règle du type de la
règle du delta, nous allons à nouveau nous intéresser à la
dérivée de E par rapport à Wji et essayer à
nouveau de montrer que :
en prenant pour définition de E l’équation 1.5.
Nous allons appliquer la même méthode que précédemment et
écrire :
À partir de l’équation 1.9 nous voyons que le second facteur
peut s’écrire :
Nous allons maintenant définir un nouveau δ :
Nous pouvons maintenant réécrire notre équation
1.11 :
Donc, si nous voulons avoir une règle de gradient, nous
devons faire en sorte que nos poids varient suivant une règle du type :
Tout le problème est donc maintenant de voir ce que peuvent
être
les valeurs des δj pour chacune des unités uj du
réseau ; nous allons montrer qu’il est possible
de calculer récursivement les δj en
rétro-propageant les signaux d’erreur à travers le réseau.
Nous allons donc décomposer δj en deux termes :
Par l’équation 1.10 on obtient :
Si uj est une unité de la couche de sortie, on peut écrire
comme pour un réseau bi-couches :
Nous trouvons, en remplaçant dans 1.12 :
|
δj = (Tj − Oj) f′j(Nj)
(1.13) |
et ce, pour toutes les unités uj appartenant à la couche de
sortie.
Pour les unités n’appartenant pas à la couche de sortie, nous
calculons ∂ E/∂ Oj en le décomposant en deux termes :
En remplaçant dans 1.12 :
Nous pouvons résumer tout cela en trois équations :
|
δj = (Tj − Oj) f′j(Nj)
(1.15) |
L’équation 1.14 indique la règle à appliquer pour
faire varier les poids en fonction du signal d’erreur, 1.15
montre comment on calcule ce signal pour les unités des couches de
sortie et 1.16 indique comment calculer ce signal par
rétro-propagation pour les unités placées dans
les couches cachées.
On voit donc que, dans ce cas, l’application de la règle du delta se fait en
deux phases : lors de la première phase, on calcule à partir du
vecteur d’entrée le vecteur de sortie. Puis on le compare au vecteur
théorique et on en déduit un signal d’erreur δj
pour chaque unité
de la couche de sortie. Lors de la seconde phase, le signal d’erreur est
rétro-propagé à travers le réseau et les changements dans les
poids sont effectués pour chacune des couches.
On a ainsi implanté une technique de rétro-propagation du
gradient.
Les problèmes associés à cette méthode sont les suivants :
tout d’abord, la surface définie par la
fonction d’erreur dans le cas des réseaux multi-couches n’est pas
concave et peut avoir un certain nombre de minima locaux ; une méthode de
plus grande pente ne garantit donc pas d’atteindre le minimum absolu.
Ensuite, la
procédure garantit qu’il y aura apprentissage mais ne dit pas en combien
de temps. Enfin, les équations montrent que cette technique
préserve la symétrie des coefficients, ce qui n’est souvent pas
souhaitable.
Nous allons maintenant examiner quelques techniques permettant de régler
(partiellement) ces problèmes.
1.4 Astuces techniques
1.4.1 La fonction d’activation
On choisit généralement comme fonction d’activation une fonction
de type sigmoïde :
θj joue ici un rôle identique à un seuil.
On remarquera que la dérivée de la fonction prend son maximum en 0.5,
ce qui veut dire que ce sont les poids proches de 0.5 qui sont les plus
modifiés, ou encore que les connexions dont on sait déjà
qu’elles sont actives ou inactives (proches de 1.0 ou de 0.0) sont les
moins modifiées. Ceci contribue à la stabilité du réseau.
On remarquera également que la fonction ne peut atteindre 1.0 ou 0.0
que pour des poids infinis.
1.4.2 Le taux d’apprentissage
On constate, en regardant les équations, que plus le taux d’apprentissage
est grand et plus les poids changent vite, ce qui permet un apprentissage
rapide. En revanche, une méthode du gradient, pour être stable,
nécessite un taux d’apprentissage aussi petit que possible. Il faut
donc trouver le taux d’apprentissage le plus grand possible sans provoquer
d’oscillation. Une méthode consiste à inclure un terme de
momentum et de réécrire l’équation du delta :
| Δ Wji(n+1) = η δj Oi + α Δ Wji(n)
|
α est une constante qui permet de pondérer la variation
présente en fonction de la variation précédente. Cela
empêche le système d’osciller avec de hautes fréquences.
On peut également faire varier le coefficient d’apprentissage et
le coefficient de momentum suivant la
règle suivante : on calcule un coefficient de corrélation
C(n) par10 :
| C(n) = ≪ Δ Wji(n),Δ Wji(n−1) ≫
|
Si C(n)<0 on prend alors :
Si au contraire C(n)>0 :
Il est parfois nécessaire de borner α et η.
On peut également légèrement améliorer la règle
d’apprentissage sur la variation des coefficients en n’augmentant
α et η que si C(n) est supérieur d’au moins 5%
à sa précédente valeur. Cela stabilise l’apprentissage.
1.4.3 Comment briser la symétrie
Une méthode traditionnellement utilisée pour briser la
symétrie du problème consiste à prendre au départ des poids petits mais
aléatoires.
1.4.4 Comment éviter les minima locaux
Une méthode pour éviter les minima locaux est d’utiliser
un recuit simulé. Le recuit simulé s’inspire, dans son principe, du
phénomène de recuit en thermodynamique. Il consiste,
très informellement, à introduire une imprécision autour de la courbe de la
fonction énergie. De ce fait, les minima locaux, qui sont généralement des
<< petits creux >> dans la courbe, sont << effacés >> et l’on atteint ainsi
le minimum global, avec une certaine imprécision. Une fois que l’on a
atteint ce minimum, on réduit lentement le degré d’imprécision et par
raffinement successif on atteint, avec la précision maximale, le minimum
absolu11.
1.5 Les réseaux de neurones logiques (ALN)
1.5.1 Présentation générale
L’apparition des réseaux de neurones logiques (ALN : Adaptive Logical Network en
anglais) remonte au milieu des années 70. Il s’agit également de réseaux
fonctionnant en
apprentissage supervisé : des exemples sont présentés au réseau,
une sortie est calculée, on compare la sortie calculée à la sortie
théorique et on modifie en conséquence le réseau, jusqu’à ce que
l’on soit satisfait de l’apprentissage. Cependant, la structure des
réseaux logiques est complètement différente de celle des réseaux
utilisant des techniques de rétro-propagation du gradient.
Un neurone dans un ALN est une porte logique à deux entrées
(gauche et droite) booléennes et une sortie booléenne. Cette porte
peut être une porte OU dont la sortie est le résultat du OU
logique entre les deux entrées, une porte ET (la sortie est le
résultat du ET logique entre les deux entrées), une porte DROITE
(la sortie est la valeur de l’entrée de droite) ou une porte GAUCHE
(la sortie est la valeur de l’entrée de gauche). Un réseau de neurones
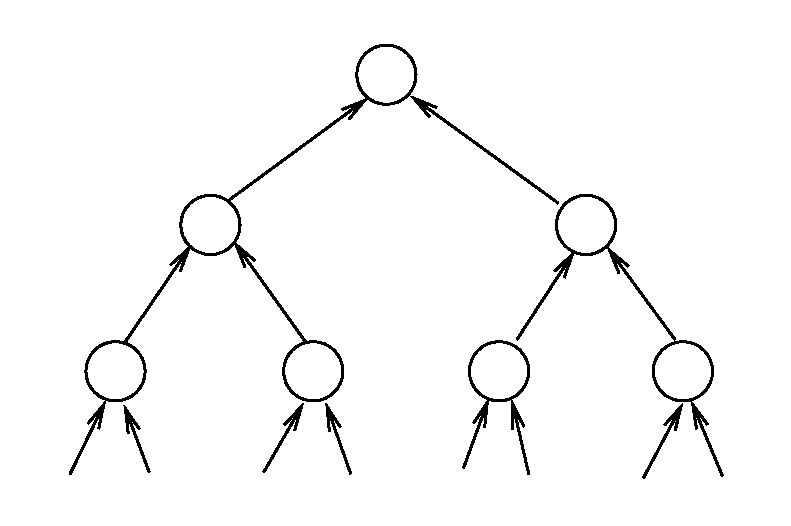
logiques est un arbre binaire où chaque nœud est un neurone
élémentaire. Un réseau de profondeur n calcule donc 1 bit en sortie
en fonction de 2n−1 bits en entrée. Ainsi, le réseau
représenté sur la figure 1.1 permettrait, par exemple, de
calculer le bit de parité d’un octet (8 bits).
| Figure 1.1: Exemple d’ALN à 8 entrées |
L’ensemble des résultats présentés dans ce chapitre dérivent des
travaux et des articles du professeur William Armstrong et de son
équipe [ALLR90, AG79, ALLR91].
1.5.2 Apprentissage
L’apprentissage dans les réseaux logiques se fait par la modification des
fonctions des portes logiques. Au début, la valeur des fonctions des
portes logiques est aléatoire. Puis, par présentation d’exemples et
comparaison de la sortie théorique et de la sortie calculée, on modifie
la valeur des fonctions de certaines portes. Le problème est de
déterminer quelles sont les portes dont la fonction doit être
modifiée, et comment la modifier.
La première notion que l’on peut définir est celle de responsabilité. Un nœud est dit responsable si le changement de
sa valeur de sortie change la valeur de la sortie du réseau, toutes les
autres sorties restant les mêmes (sauf, bien sûr, celles dépendant
directement du nœud modifié). On peut donc définir récursivement, en
partant de la racine de l’arbre, la responsabilité d’un nœud : ainsi,
considérons un nœud ET qui est responsable. Si une entrée x de
ce nœud vaut 0, alors la valeur de l’entrée opposée est sans
importance. En revanche, si la valeur de x est 1, alors le nœud fils
relié à l’autre entrée est responsable de la valeur de
sortie12.
| Fonction | (0,0) | (0,1) | (1,0) | (1,1) |
| ET | 0 | 0 | 0 | 1 |
| OU | 0 | 1 | 1 | 1 |
| GAUCHE | 0 | 0 | 1 | 1 |
| DROITE | 0 | 1 | 0 | 1 |
| Tableau 1.1: Valeur de sortie en fonction des entrées |
Il faut également remarquer (table 1.1) que le type de la
fonction n’a de l’influence que lorsque l’entrée est (0,1) ou (1,0).
C’est donc seulement pour ces valeurs en entrée que l’on peut adapter
la valeur de sortie, et donc la fonction. Une technique simple consiste à
associer, pour chaque neurone, à l’entrée (0,1) un compteur C01
et à l’entrée (1,0) un compteur C10. En phase
d’apprentissage, lorsque l’entrée est (0,1), que le neurone est
responsable et que la sortie théorique est 1, alors le compteur est
incrémenté ; si la sortie théorique est 0, alors le compteur est
décrémenté. On applique le même algorithme pour le compteur
C10 et l’entrée (1,0). À chaque étape, la sortie d’un neurone
est calculée à partir de la valeur des deux compteurs. Si les compteurs
sont positifs tous les deux, alors le neurone se comportera comme un OU. Si les deux compteurs sont négatifs, alors le neurone se comporte
comme un ET. Si le compteur C01 est positif et le compteur
C10 négatif,
alors la fonction du neurone est la fonction DROITE ;
symétriquement, si le compteur C10 est positif et le compteur
C01 négatif, la fonction est GAUCHE. On obtient ainsi un
système auto-adaptatif qui tend à récompenser les neurones qui se
comportent bien et à punir les neurones qui se comportent
mal13.
Malheureusement, cette technique se révèle en pratique trop simple ;
elle a, en effet, tendance à entraîner le réseau vers un optimum local.
D’autres techniques ont été développées, basées sur une notion de
responsabilité heuristique d’un nœud et non plus sur la
responsabilité << simple >>. Elles sont décrites dans
[ALLR90, AG79, Arm76]. On peut rapidement indiquer la plus
simple : le nœud situé à la racine de l’arbre est toujours
heuristiquement responsable. Si un nœud est heuristiquement responsable et
qu’une de ses entrées n’est pas égale à la valeur de sortie
désirée du réseau, alors cette entrée est une erreur. Si le signal
de droite est une erreur, alors le nœud de gauche est heuristiquement
responsable. Chaque neurone mémorise la dernière valeur du signal
d’erreur pour chaque entrée ; le nœud de gauche est également
responsable si le signal de droite n’est pas une erreur, mais est égal
au dernier signal d’erreur pour l’entrée droite. Bien entendu, la
responsabilité heuristique du nœud de droite est déterminée
symétriquement. Cette stratégie est appelée par le professeur
Armstrong the latest error strategy. Avec cette technique, on
améliore considérablement les capacités d’apprentissage des
réseaux.
1.5.3 Apprentissage de fonctions numériques
Les réseaux logiques ne sont pas limités à l’apprentissage de
fonctions logiques. Ils peuvent également apprendre des fonctions de
variables entières ou discrètes, à valeurs entières ou discrètes. La
méthode naïve, qui consiste à coder en base 2 les valeurs
d’entrée et de sortie, est
cependant insuffisante. En effet, par un semblable mécanisme, on ne
différencie pas les bits de poids faibles des bits de poids forts. Or il
est clair que la présence ou l’absence d’un bit de poids fort est plus
importante que la présence ou l’absence d’un bit de poids faible. Il faut
donc raffiner la méthode.
On commence tout d’abord par effectuer une
quantification en k niveaux des valeurs d’entrée14. La phase suivante est un peu plus complexe ;
on prend la première valeur de quantification et on lui associe un
vecteur aléatoire d’un espace de Hamming de dimension n. Récursivement, si
j’ai associé aux i−1 premières valeurs de quantification, un
vecteur de mon espace de Hamming, j’associe à la i-ème valeur de
quantification un vecteur
aléatoire du même espace de Hamming se trouvant à une
distance de Hamming p du vecteur
associé à la valeur i−1 (cette technique de codage est décrite
dans [SS90]). L’intérêt de cette méthode est qu’elle
maintient une relation de localité dans l’espace de Hamming entre
deux éléments proches au sens de la distance euclidienne, tout en
supprimant le problème lié aux bits de poids forts et de poids
faibles.
On utilisera le même mécanisme pour coder
les valeurs de sortie du réseau. Il faut cependant se
rappeler qu’un réseau logique ne pouvant fournir qu’un seul bit en
sortie, il faudra utiliser autant de réseaux qu’il y aura de bits
utilisés pour coder la variable de sortie.
Le choix des valeurs de n et de p est complexe. n doit
être suffisamment grand pour garantir l’unicité des vecteurs de
l’espace de Hamming codant les niveaux de quantification, mais pas
trop grand car cela augmente la taille des arbres et donc les temps de
calcul. Ce problème est particulièrement critique pour le codage
de la valeur de sortie, car ajouter un bit dans le codage de la
variable de sortie revient à rajouter un arbre entier.
De même, le choix de p doit répondre à deux
contraintes. D’une part p doit être suffisamment petit pour
conserver le concept de localité ; deux vecteurs pris au hasard dans
un espace de Hamming de dimension n ont une distance moyenne de
n/2, donc p doit être assez nettement inférieur à n/2.
D’autre part, il est intéressant de choisir pour la variable de
sortie une valeur de p relativement grande ; en effet, si la valeur
de sortie calculée par le réseau est différente de tous les
vecteurs servant à coder les variables de quantification, on choisit
le vecteur le plus proche au sens de la distance de Hamming. Plus les
vecteurs de codage sont éloignés les uns des et autres et plus le
décodage basé sur la méthode de distance minimale est efficace.
1.5.4 Avantages des ALN
Les ALN présentent un certain nombre d’avantages par rapport à
l’approche des réseaux à rétro-propagation du gradient :
-
Apprentissage paresseux :
- on n’a besoin de s’intéresser
qu’aux parties de l’arbre qui sont responsables. Les autres sont sans
intérêt, d’où un gain de temps certain.
- Évaluation paresseuse :
- lorsque le réseau est appris, on peut
utiliser des techniques d’évaluation paresseuse pour améliorer la
vitesse de calcul. Ainsi, lorsque l’on a calculé la valeur de
l’entrée gauche d’un neurone ET, et que cette valeur est 0, il
est inutile d’évaluer le sous-arbre de droite. De même pour une
porte OU, si la valeur est 1, alors il est également inutile
d’évaluer le sous-arbre de droite. On gagne ainsi un temps
précieux dans l’évaluation.
- Pouvoir de représentation :
- les ALN ont la capacité de
pouvoir représenter sans difficulté des fonctions présentant des
discontinuités, ou dont la dérivée présente une
discontinuité. Les réseaux utilisant des sigmoïdes
<< arrondissent >> les discontinuités des fonctions.
- Possibilité d’implantation hardware :
- une fois qu’un
apprentissage est terminé, il est possible de construire un réseau
électronique reprenant l’architecture logique apprise. De semblables
réseaux ont des vitesses de calculs incomparablement supérieures
à n’importe quel autre système, le calcul d’une valeur
s’évaluant en nanosecondes !
- Insensibilité aux perturbations :
- une des caractéristiques
essentielles des ALN est leur insensibilité aux perturbations.
Supposons que nous disposions d’un réseau aléatoire et que nous
introduisions un bruit sur chacune des entrées i.e., la
probabilité qu’un bit soit changé en son opposé est p. Quelle
est l’influence sur la couche suivante ? Il est aisé de prouver que
la probabilité est p−p2/4. En effet, la probabilité de
changement pour une porte ET ou OU est p−p2/2 et pour
une porte DROITE ou GAUCHE est p15. Donc, la probabilité
que la valeur d’un bit soit changé dans la couche n est donnée
par la loi : pn+1= pn−pn2/4 avec p0=p. On peut voir
dans la table 1.2 une évaluation numérique de cette
loi (en abscisse, nombre de couches, en ordonnée probabilité p
de modification de chaque bit dans la couche d’entrée).
| | 2 | 4 | 6 | 8 | 10 | 12 | 14 | 16 | 18 | 20 |
| 1.0 | 0.60 | 0.45 | 0.36 | 0.30 | 0.26 | 0.23 | 0.20 | 0.18 | 0.17 | 0.15 |
| 0.8 | 0.54 | 0.41 | 0.33 | 0.28 | 0.24 | 0.22 | 0.19 | 0.18 | 0.16 | 0.15 |
| 0.6 | 0.44 | 0.36 | 0.30 | 0.26 | 0.23 | 0.20 | 0.18 | 0.17 | 0.15 | 0.14 |
| 0.4 | 0.33 | 0.28 | 0.24 | 0.21 | 0.19 | 0.17 | 0.16 | 0.15 | 0.14 | 0.13 |
| 0.2 | 0.18 | 0.16 | 0.15 | 0.14 | 0.13 | 0.12 | 0.12 | 0.11 | 0.10 | 0.10 |
| Tableau 1.2: Mesure d’insensibilité d’un ALN |
On constate donc que les ALN sont très insensibles au bruit, et que
cette insensibilité est d’autant plus grande que l’arbre est
profond. Or, la reconnaissance de forme s’appuie sur cette
propriété fondamentale : une petite perturbation des entrées
doit peu modifier la sortie. L’insensibilité remplace dans les ALN
la continuité que l’on trouve dans les réseaux à
rétro-propagation.
L’approche des ALN est relativement peu connue aujourd’hui et
mérite pourtant une grande attention. Ils permettent de réaliser
des implantations rapides et des simulations
efficaces, car uniquement en nombres entiers. Nous nous
sommes attardés sur ce sujet car il est peu décrit dans la
littérature classique, particulièrement en langue française.
Espérons que cet oubli sera rapidement réparé.
1.6 Les réseaux de Kohonen
1.6.1 Principes généraux
Les réseaux de Kohonen sont des réseaux à
apprentissage non supervisé.
Nous n’en dirons qu’un mot rapide. On
peut se reporter pour plus de détails à [Koh88].
Dans un réseau de Kohonen, il n’y a pas apprentissage par présentation
d’exemple, mais auto-adaptation à des stimuli
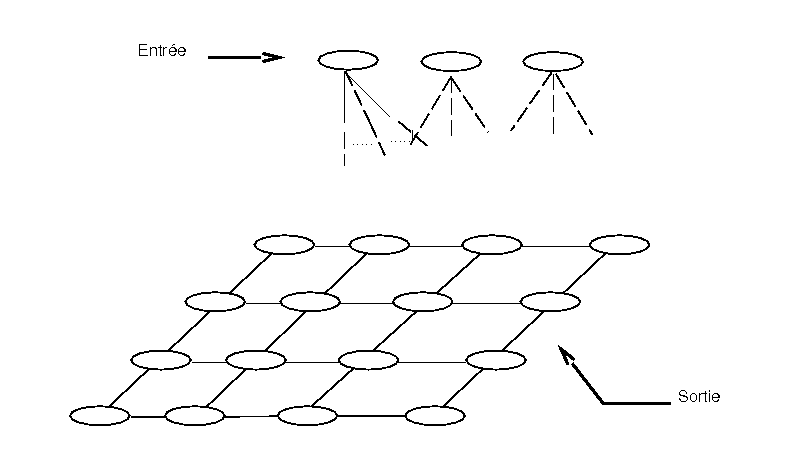
d’entrée. Le réseau est constitué de deux couches seulement.
Chaque neurone de la couche d’entrée alimente tous
les neurones de la couche de sortie, et tous les neurones de la couche
de sortie sont connectés entre eux (figure 1.2).
| Figure 1.2: Carte de Kohonen |
Un seul neurone de la
couche de sortie est actif lorsqu’une entrée est présentée. Le
principe général d’un réseau de Kohonen est de faire une
classification des entrées et de fournir une sortie qui soit la
même pour des entrées proches.
1.6.2 Calcul de la valeur de sortie
Notons xi les valeurs en provenance de la couche d’entrée
(couche 1). On pose pour chaque neurone j de la couche de sortie
(couche 2) :
|
| | Ej(n) | = | | (1.17) |
| Vj(n) | = | | (1.18) |
| Sj(n) | = | f(Ej(n)+Vj(n)) | (1.19) |
| Dj | = | | (1.20) |
| p | tel que | | (1.21) |
|
-
Wij :
- matrice des poids des connexions entre la couche 1 et
la couche 2.
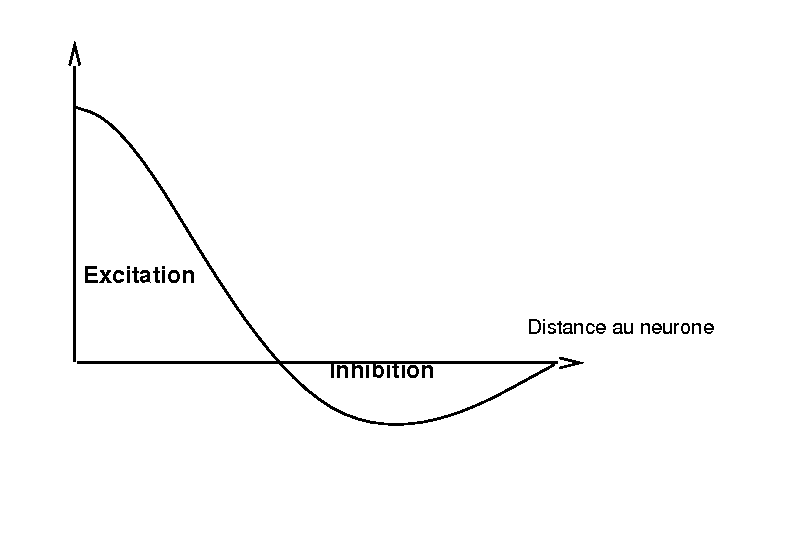
- A(j,k) :
- fonction d’atténuation. La valeur de A(j,k) est
fonction de la distance d(j,k) du neurone j au neurone k dans la carte de
sortie. La valeur de A(j,k) en fonction de la distance d est
représentée sur la figure 1.3.
| Figure 1.3: Fonction d’atténuation |
La fonction renforce l’influence des neurones très proches,
considère les neurones plus éloignés comme inhibiteurs, les
neurones très éloignés n’ayant aucune influence.
- f(x) :
- fonction sigmoïde.
- Ej(n) :
- influence des neurones de la couche
d’entrée sur le neurone j de la couche de sortie à l’étape n.
- Vj(n) :
- influence des autres neurones de la
couche de sortie sur le neurone j de la même couche à l’étape
n.
- Sj(n) :
- état du neurone j de la couche de sortie à
l’étape n.
- Dj :
- distance quadratique entre le vecteur d’entrée et le
vecteur pondération.
- p :
- neurone qui sera actif. p est le neurone pour lequel la
distance, entre le vecteur pondération et le vecteur d’entrée, est la
plus faible.
Le mécanisme est donc très simple. On présente au réseau un
exemple et il calcule quel neurone en sortie sera actif.
1.6.3 Apprentissage
L’apprentissage a pour but d’améliorer les capacités de
discrimination du réseau. La formule de modification des poids des
coefficients est :
| Wij(k)=Wij(k−1)+ η (xi−Wij(k−1)) |
Seul le neurone excité et ses voisins modifient leur poids. Les
voisins d’un neurone j sont les neurones se trouvant à
l’intérieur d’un cercle de rayon R autour de j.
Au début de l’apprentissage, les valeurs de R et η sont
relativement grandes. On diminue ces valeurs pendant l’apprentissage
de façon à rendre le réseau aussi discriminant que possible.
1.7 Conclusion
Depuis quelques années, les réseaux
de neurones ont connu une popularité croissante, pour devenir
aujourd’hui un des sujets de recherche les plus courus. Il faut noter que
l’approche connexionniste est complètement différente de l’approche
traditionnelle. L’approche classique consiste à trouver un algorithme
performant et à utiliser le langage et le processeur adaptés. Elle
conduit à affirmer : je dispose d’une solution algorithmique du
problème P qui nécessite n opérations. Le mécanisme
connexionniste conduit, au contraire, à des propositions du style :
l’architecture A du réseau d’automates de type T, agrémentée
de la formule F de calcul des coefficients d’interaction permet
de résoudre le problème P.
L’approche connexionniste semble bien adaptée à des
problèmes d’optimisation ou de reconnaissance de formes.
Des exemples
d’utilisations réussies de réseaux de neurones ont été donnés
par Hopfield et Tank en optimisation (programmation linéaire par exemple),
électronique (conversion analogique numérique), traitement du signal, et
par d’autres équipes dans le domaine des jeux (Tic-tac-toe,
Backgammon), de la reconnaissance de caractères, et des systèmes
experts (diagnostic médical).
L’approche connexionniste présente plusieurs avantages : le premier est que
la connaissance est distribuée dans le réseau et que la panne d’une
partie du réseau n’empêche pas forcément l’ensemble du
système de fonctionner (quand il ne s’agit pas d’une simulation sur une
machine classique, ce qui est en général le cas).
Surtout, ces systèmes ont une capacité à la
généralisation16.
Comme l’ont montré plusieurs équipes, lorsque le réseau a
appris certaines formes (des lettres par exemple),
il est capable de reconnaître
ces mêmes formes légèrement déformées, sans qu’il soit
besoin de refaire un apprentissage. Enfin, la solution d’un problème
peut, pour certains types de réseaux, être donnée de façon
quasi-instantanée, puisqu’il suffit d’effectuer une passe à travers le
réseau.
Les réseaux neuronaux ne résoudront pas, du jour au lendemain,
l’ensemble des problèmes de l’informatique. En particulier, on doit
toujours prendre soin de comparer les résultats obtenus avec les
réseaux de neurones formels et les résultats obtenus par des
méthodes classiques (statistiques par exemple) et se méfier des
phénomènes de mode qui accompagnent chaque nouvelle
méthode. Il s’agit cependant
d’un champ de recherche complètement nouveau, et d’une approche
absolument différente qui mérite d’être examinée avec
intérêt.
Leur développement ne pourra se faire que par un développement
conjoint des méthodes théoriques et des moyens de calcul (circuits
VLSI adaptés). Le nombre croissant de conférences et de publications,
aussi bien dans les revues d’informatique que d’électronique, semble
montrer que le sujet est pris très au sérieux actuellement.
Références
-
[AG79]
-
William Armstrong and Jan Gecsi.
Adaptation algorithms for binary tree networks.
IEEE transactions on systems, man and cybernetics, 9(5), 1979.
- [ALLR90]
-
William Armstrong, Jiandong Liang, Dekang Lin, and Scott Reynolds.
Experiments using parsimonious adaptative logic.
Technical Report TR 90-30, University of Alberta, Edmonton, Alberta,
Canada, 1990.
- [ALLR91]
-
William Armstrong, Jiandong Liang, Dekang Lin, and Scott Reynolds.
Experience using adaptative logic networks.
In Proceedings of the IASTED International Symposium on
Computers, electronics, communication and control, 1991.
- [Arm76]
-
William Armstrong.
Adaptive boolean logic element.
US patent 3 934 231, January 1976.
- [BRS91]
-
P. Bourret, J. Reggia, and M. Samuelides.
Réseaux neuronaux.
Teknea, 1991.
ISBN : 2977100160.
- [DN86]
-
E. Davalo and P. Naim.
Des réseaux de neurones.
Eyrolles, 1986.
- [HKP91]
-
John Hertz, Anders Krogh, and Richard G. Palmer.
Introductions to the theory of neural computing.
Addison Wesley, 1991.
ISBN: 0-201-51560-1.
- [HN90]
-
Robert Hecht-Nielsen.
Neurocomputing.
Addison-Wesley, 1990.
ISBN: 0-201-09355-3.
- [Koh88]
-
Teuvo Kohonen.
Self organization and associative memory.
Springer Verlag, 1988.
ISBN: 0-387-51387-6.
- [MP43]
-
W. S. McCulloch and W. A. Pitts.
A logical calculus of the ideas immanent in nervous activity.
Bulletin of mathematics and biophysics, 5, 1943.
- [MP69]
-
Marvin Minsky and Seymour Papert.
Perceptrons : an introduction to computational geometry.
MIT Press, 1969.
ISBN: 0-262-63111-3.
- [MPRV87]
-
R. J. McEliece, E.C. Posner, E.R. Rodernich, and S.S Venkatesh.
Capacity of the hopfield associative memory.
IEEE transaction on information theory, 33:461–482, 1987.
- [pls87]
-
Bibliothèque pour la science.
Le cerveau.
Payot, 1987.
ISBN 2-902918-24-0.
- [Ros58]
-
F. Rosenblatt.
The perceptron: a probabilistic model for information storage and
organization in the brain.
Psychoanalysis review, 65, 1958.
- [Ros62]
-
Fred Rosenblatt.
Principles of neurodynamics.
Spartan Books, 1962.
LC Card Number: 62012882 /L/r85.
- [Rum86]
-
David E. Rumelhart.
Parallel Distributed Processsing : Explorations in the
Microstructure of cognition, Volume 1 : Foundation, chapter Learning
internal representations by error propagation.
MIT Press, 1986.
ISBN: 0-262-18120-7.
- [Sou86]
-
Françoise Fogelman Soulié.
Learning in automate networks.
In Artificial intelligence. CIIAM, 1986.
- [SS90]
-
Derek Smith and Paul Stanford.
A random walk in hamming space.
In Proceedings of the International Joint Conference on Neural
Networks, volume 2, 1990.
Retour à ma page principale
Le téléchargement ou la reproduction des documents et photographies
présents sur ce site sont autorisés à condition que leur origine soit
explicitement mentionnée et que leur utilisation
se limite à des fins non commerciales, notamment de recherche,
d'éducation et d'enseignement.
Tous droits réservés.
Dernière modification:
10:59, 17/08/2025